Data
Greater Poland Spoken Corpus
68 Speakers; 69,720 Word tokens
(Kaźmierski, Kul & Zydorowicz in press)
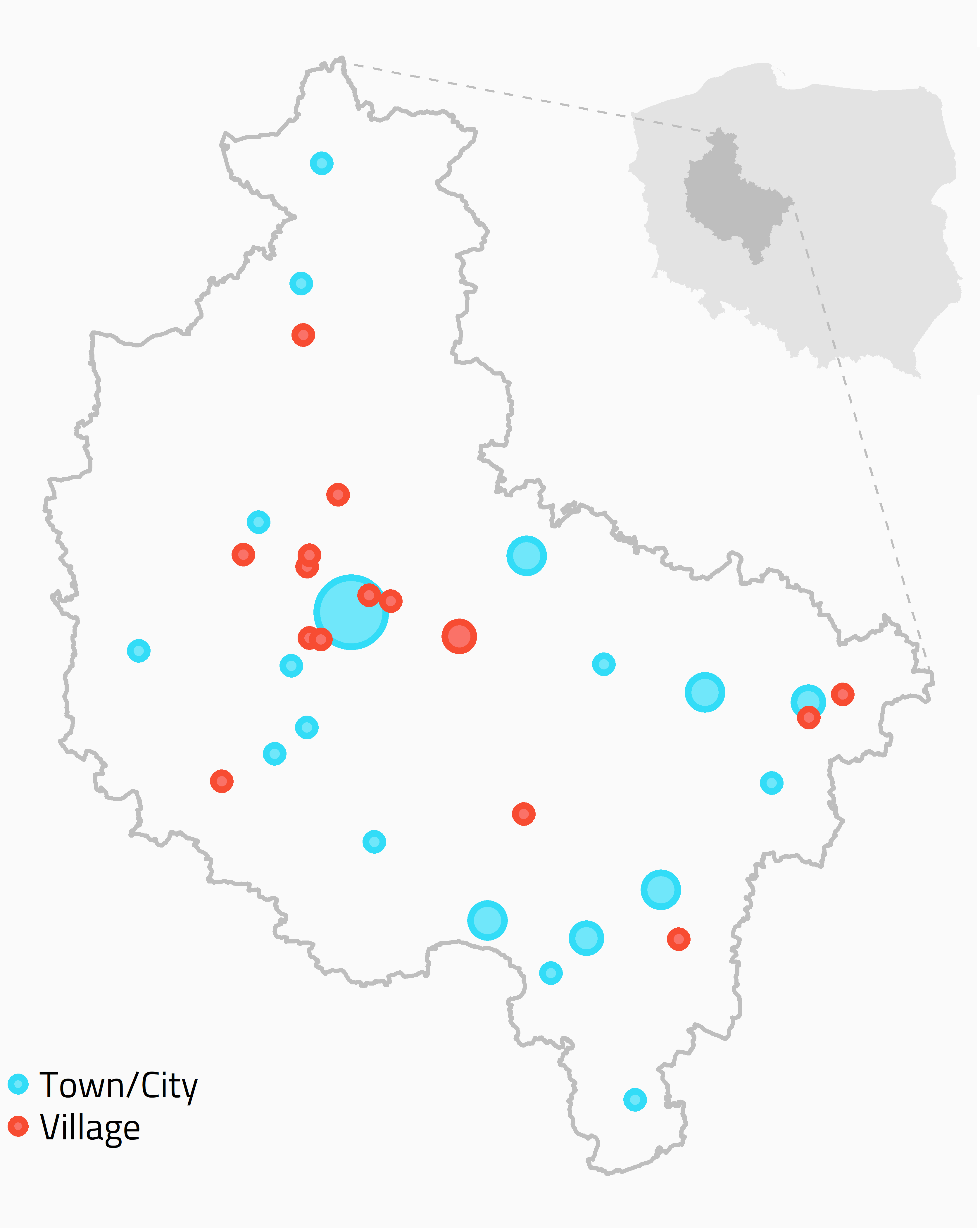
Data extraction
 Transcripts hand-aligned at breath-group level in Praat (Boersma & Weenink 2016)
Transcripts hand-aligned at breath-group level in Praat (Boersma & Weenink 2016)
 Corpus creation, management and querying with LaBB-CAT (Fromont & Hay 2012)
Corpus creation, management and querying with LaBB-CAT (Fromont & Hay 2012)
→ Force-aligned at word and phoneme level
→ Fricative initial (ɕ ʂ ʑ f s v x z) C₁C₂V...content words
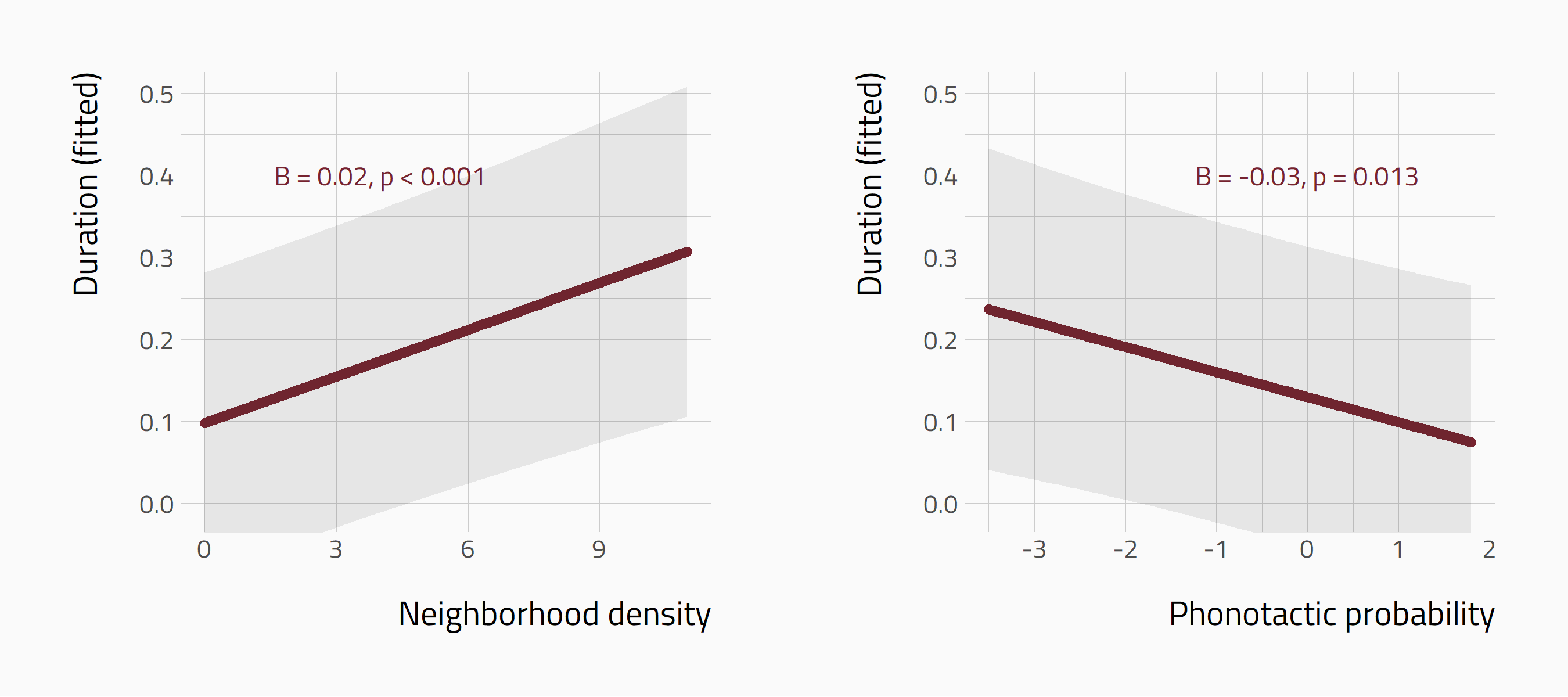
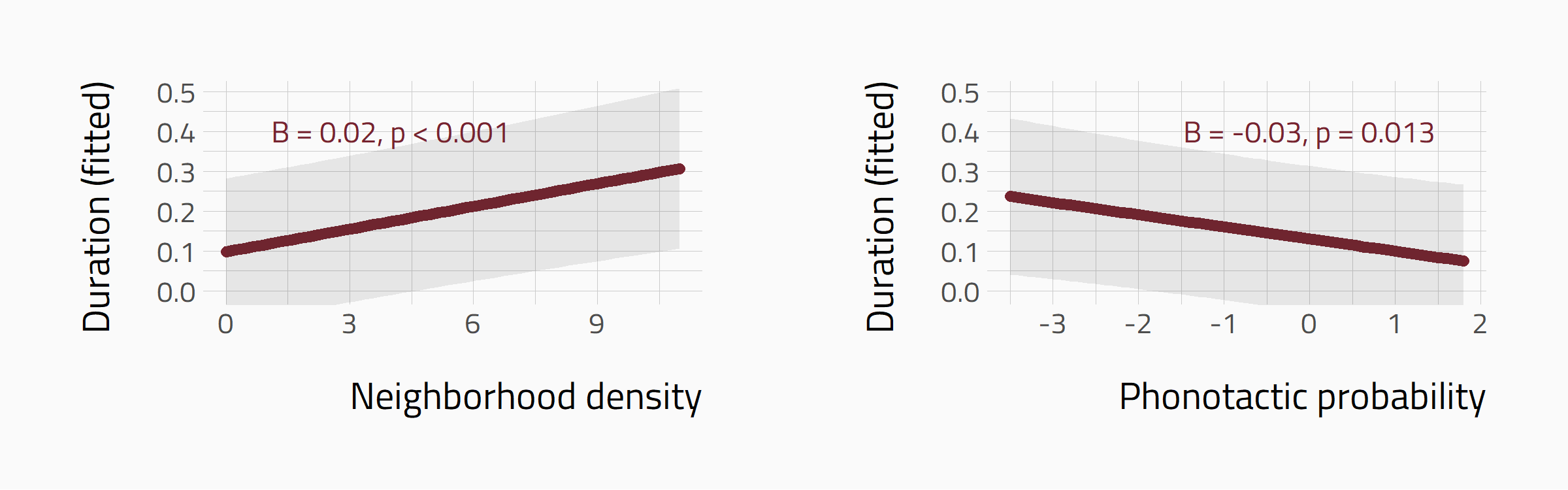
Divergent effects of Neighb. dens. and Phon. prob.
Thank you!
Neighborhood density and phonotactic probability show differential effects on duration of Polish fricatives
This research was supported by National Science Center (Poland) grant no. UMO-2017/26/D/HS2/00027
kamil.kazmierski@wa.amu.edu.pl